Member-only story
Training Data vs. Test Data in Machine Learning — Essential Guide
Read on to understand the difference between training data vs. test data in machine learning.
Knowing the difference and ensuring you’re using both the right way is essential. In this article, we will discuss training data vs. test data and explain more about each.
It aims to be an introduction for anyone who needs to know the difference between the various dataset splits while training Machine Learning models.
Machine Learning — Soft Introduction
Machine learning (ML) is a branch of artificial intelligence (AI) that uses data and algorithms to mimic real-world situations so organizations can forecast, analyze, and study human behaviors and events.
ML usage lets organizations understand customer behaviors, spot process- and operation-related patterns, and forecast trends and developments. Many companies, in fact, have made ML an integral part of how they operate.
Constructing ML algorithms depends on how they will collect data. And more often than not, the information gathered is categorized into three types.
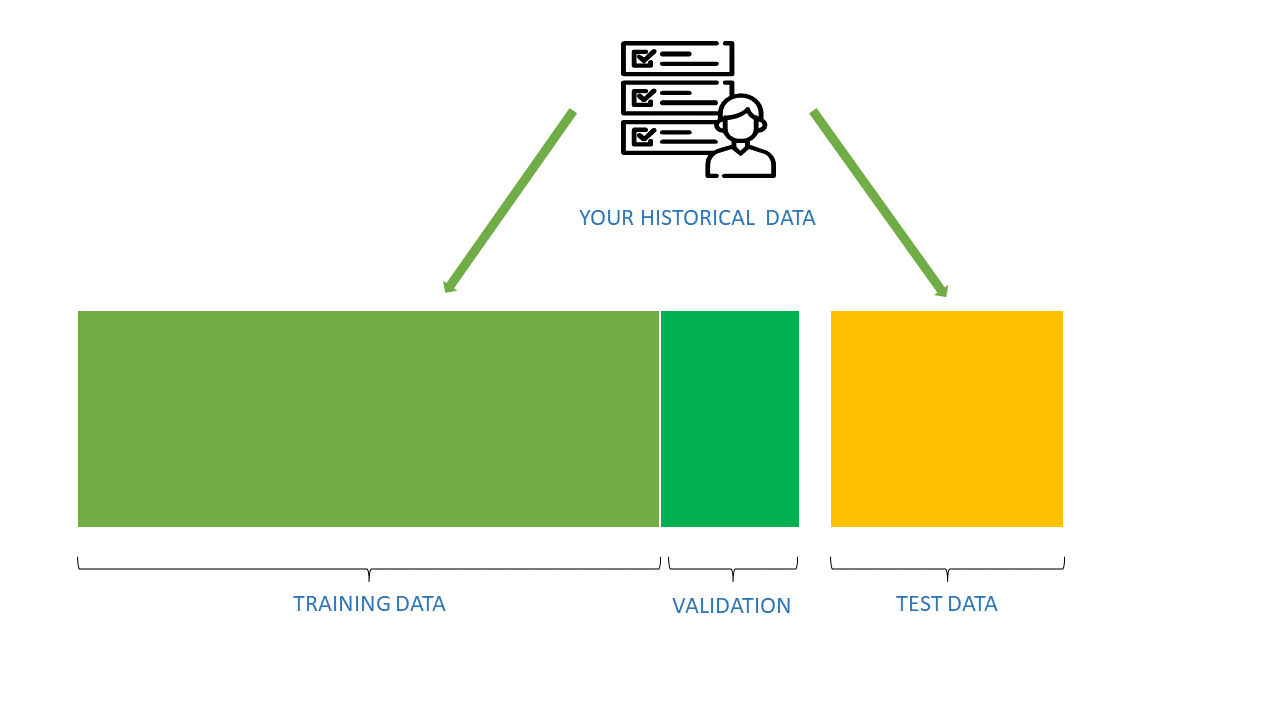
The machine learning process uses three data sets in creating algorithms:
- training data,
- validation data,
- and test data.
Let us distinguish one from the others.
What is the Training Dataset in Machine Learning?
Training data is used to train a model to predict an expected outcome.
An outcome is based on the result of regression or classification problems, for example, churn prediction, sales lead scoring prediction, or time-series forecast.
The algorithm’s design thus focuses on the outcome of the expected or predicted result.
Training data is the actual dataset we use to train the model. We can say that the model and from this data.
Training data teaches an algorithm to extract relevant aspects of the outcome. It is often the initial dataset used to make a program understand how to apply…

