
Transformers Positional Encodings Explained
In the original transformer architecture, positional encodings were added to the input and output embeddings.

Positional encodings play a crucial role in transformers, enabling them to capture the sequential order of words or tokens within a text.
It’s worth noting that, without positional information, the output of a transformer would not change if we mixed the order of the words in the input.
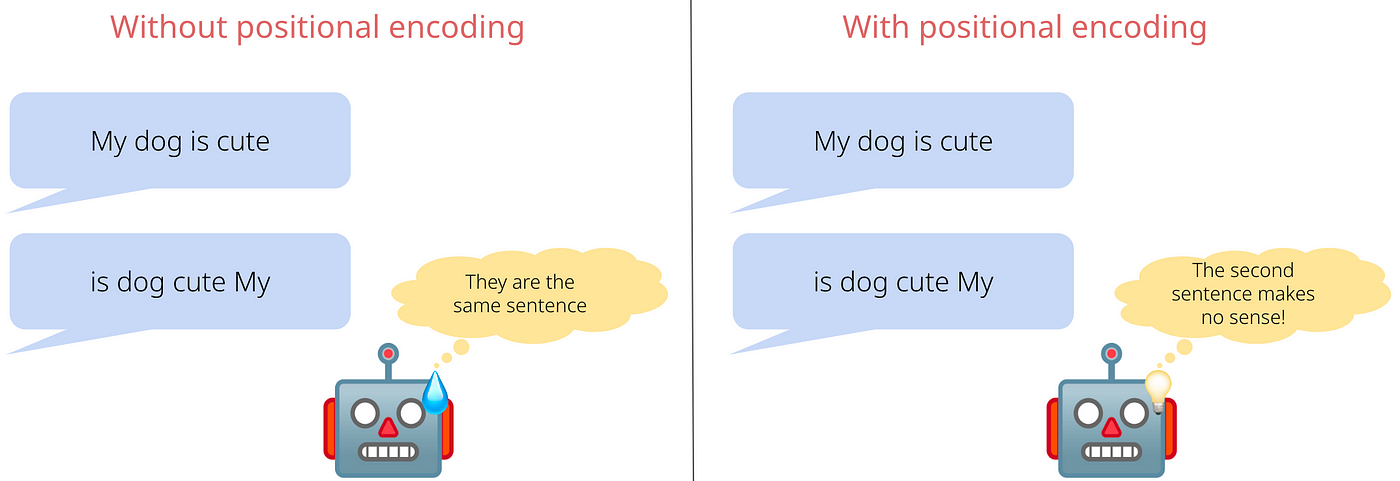
However, they also impose limitations on the maximum length of text that can be processed.
In a transformer architecture, the input text is divided into a sequence of tokens, and each token is associated with a learnable positional embedding vector.
A normal procedure to associate token and positional embeddings is to simply add them, as depicted in the image below.

In the following sections of this blog post, we will look at how these embeddings are obtained.
Absolute Positional Embeddings
Absolute positional embeddings are arguably the easiest type of embeddings to understand, so let’s start with them.
Both BERT and GPT-2 (ancestor of ChatGPT) used this type of learned positional embeddings.
If you understand token/word embeddings, the concept is identical: in the same way that the model has a token embedding table to represent all the possible tokens in the input, it also has a positional embedding table with all the possible token positions that the model supports.

These absolute positional embeddings are learned by the model which adds a hard constraint to the architecture: the positional embedding table has a limited number of rows, which means that our model is now bounded to a maximum input size!
Sinusoidal Positional Embeddings
The initial transformer proposed in Attention Is All You Need uses sine and cosine positional embeddings.
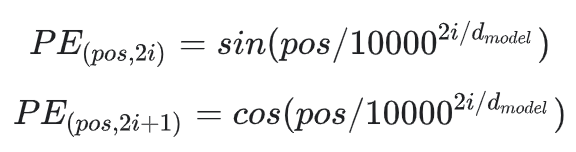
For a great explanation of how sinusoidal positional embeddings are constructed, I definitely recommend this awesome video by Batool Arhamna Haider.
What is important to note is that these sine and cosine positional embeddings aren’t learned by the model, but they are also not suited to deal with large input sizes.
As the sequence length increases, the frequency of the sinusoidal functions used in the positional embeddings becomes too high, resulting in very short periods. This can lead to inadequate representation of long-range dependencies and difficulties in capturing fine-grained positional information.
Relative Positional Encodings
Relative positional encodings were initially proposed in the paper “Self-Attention with Relative Position Representations“.
In this paper, the authors introduced a way of using pairwise distances as a way of creating positional encodings.
Theoretically, positional encodings can generalize to sequences of unseen lengths, since the only information it encodes is the relative pairwise distance between two tokens.
This type of positional encoding was also used in T5, where the authors introduced a new simplified way to calculate these pairwise distances.
At the time of writing, there are two most widely used types of relative positional encodings: RoPE and ALiBi.
There is a main trend in these new approaches: the positional information is embedded directly in the Query (Q) and Key (K) vectors that are used for scaled dot-product attention. This means that no positional embeddings are added to the token embeddings!
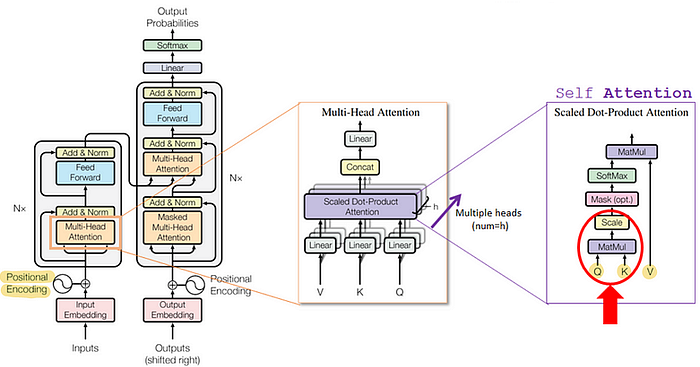
Rotary Positional Embeddings (RoPE)
Rotary positional embeddings are a type of relative positional embeddings that do not add any extra trainable parameters to the model.
Both Llama, Llama 2, and Falcon use this type of positional encoding!
When using RoPE, the Q and K vectors are separately modified to encode positional information. This modification is done with rotation matrices that are pre-computed and fixed, as seen in the gif below.

Recently, it was discovered that these embeddings can be scaled to work in longer sequences with no (or minimal) fine-tuning. This technique was called RoPE-scaling.
The idea is that, in inference, instead of rotating mθ, you can scale this rotation to be smaller and therefore work for longer sequence sizes.
There are many ways to scale the rotation, the most common one being a linear scaling mθ/N.
To deep dive into how RoPE-scaling works, I recommend reading the “Extending Context Window of Large Language Models via Positional Interpolation” paper and the original Reddit thread.
Attention with Linear Biases (ALiBi)
“Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation” introduced this positional encoding method that biases the query-key attention scores with a penalty that is proportional to their distance.
In practice, this is just slightly changing the scaled dot-product attention by adding a constant positional bias. This constant is not learned by the network!

The positional bias is simply calculated like this:

where m is a specific scalar that is set independently for each attention head.
BLOOM, BloombergGPT, and MPT use this type of positional encoding, and more language models should as the results are really impressive!
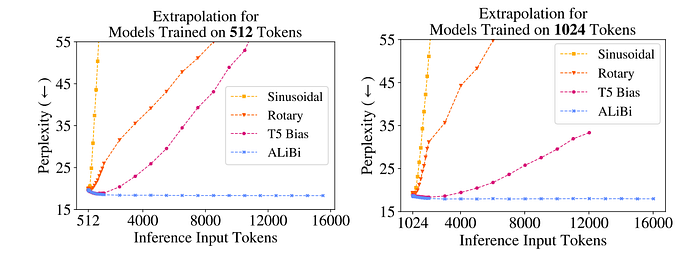
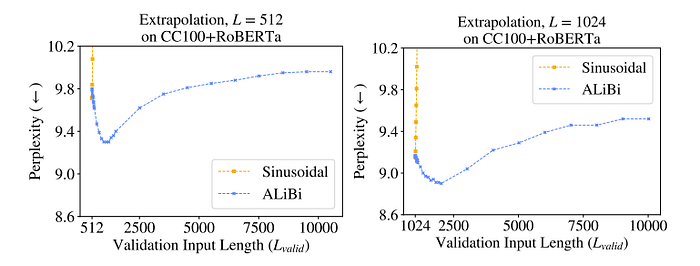
Conclusion – What is the best positional encoding?
Besides ALiBi being superior for extrapolating to 2x the context length the model was trained on, it doesn’t scale to longer sequences.
Recently, a lot of RoPE scaling methods have come up to address RoPE’s extrapolation limitations and make it scale to 8x bigger sequences:
- Linear scaling
- Rectified RoPE
- NTK-aware RoPE scaling (used in Code Llama 🦙)
- Truncated basis
Nonetheless, neither ALiBi nor RoPE are enough to solve the current input size limitations of language models.
Attention also plays a major role in limiting the language model’s ability to handle long sequences, but let’s save this topic for another blog post! 📚

