Data Engineering
Lakehouse and the evolution of Data Lake
Simplifying data infrastructure and accelerating innovation

The history of data storage starts back in the 1950s when punch cards were used for storing data generated by computers. A lot has changed since then and this article will cover one of the latest trends in the industry, Lakehouse.

Before we jump into what’s Lakehouse and how you can benefit from it, let’s have a quick overview of two data management paradigms widely used nowadays.
Data Warehouse
The architecture for Data Warehouses was developed in the 1980s to support companies in their decision-making process. The central concept relies on having historical data processed and stored in both formats, aggregated and granular.
Aggregated data contain high-level information, summarized by groups and displaying measures such as totals, averages, or sums; granular data contain information at the lowest level of detail that is relevant for the business analysis.
This data is then consumed by BI tools, where executives and other staff can visualize and analyze data in the format of reports and charts.
Data Lake
With the advent of big data, traditional architectures like the data warehouse had to be rethought. With data coming from different sources, in different formats, and usually in a bigger volume, a new paradigm needed to emerge to fill this gap. In a data lake, the data is stored in its raw format and it’s only queried when a business question arises, retrieving relevant data that can then be analyzed to help answer the question. The data is stored in cloud storage like Amazon S3, which has become one of the largest and most cost-effective storage systems in the world as it makes it possible to store practically limitless amounts of data in its native format at a low cost.

Lakehouse: The best of two worlds
Data lakes, like any emerging technology, started to reveal some of its weaknesses. Some of the key features from databases were missing, transactions were not supported, hard to enforce data quality and it relies on the eventual consistency model rather than the strong consistency model.
Eventual consistency relies on the concept that, if no new updates are made to a given data record, eventually all accesses to that record will return the last updated value whereas strong consistency offers up-to-date data but at the cost of high latency.
Databricks announced early this year, Lakehouse, a new paradigm that merges the best of the two worlds, including their names.
Lakehouse's main goal is to bring the key features from data warehouses into the data lake model and to achieve that, we have a new framework, Delta Lake.
Delta Lake is an open-source framework with the function of serving as a storage layer to Apache Spark and other big data platforms. It was developed by Databricks and has been adopted by companies such as Alibaba, McAfee, Nielsen, Tableau, Talend, and eBay.
Delta Lake brings support to ACID transactions to lakehouses. It guarantees atomicity and durability to the storage system.
In computer science, ACID (atomicity, consistency, isolation, durability) is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps. — Wikipedia
Specifically, Delta Lake performs transactional operations via LogStore API rather than accessing the storage system directly in order to enforce three factors to the storage system:
- Atomic visibility: Ensures that a file is visible in its entirety or not visible at all.
- Mutual exclusion: Ensures that only one writer is able to create or rename a file at the final destination.
- Consistent listing: Ensures that once a file is written in a directory, all future listings for that directory must return that file.
Supported Storage Systems
Delta Lake has built-in LogStore implementations for HDFS, Amazon S3, and Azure storage services.
Integrations
You can access Delta tables from Apache Spark and other data processing systems. Reading from external tables is supported by using a manifest file. In this file, there is a list of data files to read for querying a table.
Here is the list of integrations that are currently available:
- Presto
- Athena
- Redshift Spectrum (Experimental)
- Snowflake (Experimental)
- Apache Hive
More information on how to set up integration using manifest files and query Delta tables can be found at https://docs.delta.io/latest/integrations.html
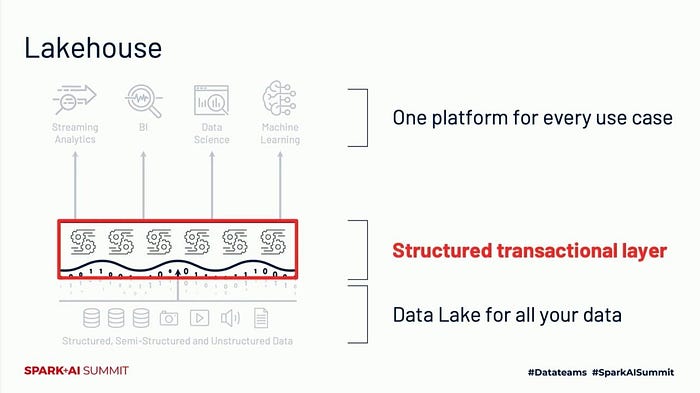
Lakehouse Architecture

The main difference between data lakes and lakehouses is the addition of a structured transactional layer.
Final Thoughts
In this article, we could see how much technology has evolved and the pace of innovation is just speeding up as technology becomes cheaper and companies need to adapt quickly to this always-changing environment. Let’s see how long it takes until the next paradigm comes up.
References:
- Keith D. Foote (April 19, 2018). A Brief History of the Data Warehouse. Retrieved from https://www.dataversity.net/brief-history-data-warehouse/
- Ben Lorica et al. (January 30, 2020). What is a Lakehouse? Retrieved from https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
- Aggregate and granular information. Retrieved from https://www.cese.nsw.gov.au/effective-practices/using-data-with-confidence-main/aggregate-granular
- Saurabh.v (July 16, 2017) Eventual vs Strong Consistency in Distributed Databases. Retrieved from https://hackernoon.com/eventual-vs-strong-consistency-in-distributed-databases-282fdad37cf7
- ACID (13 October, 2020). Wikipedia. Retrieved from https://en.wikipedia.org/wiki/ACID
- Delta Lake (2020). Delta [Source Code]. https://github.com/delta-io/delta
- Delta Lake (2020). Storage configuration. Retrieved from https://docs.delta.io/latest/delta-storage.html

