Member-only story
DeepSeek R1 Distilled Models in Ollama: Not What You Think
DeepSeek R1’s distilled models in Ollama sound like smaller versions of the original, but are they really?

Don’t have a paid Medium membership (yet)? You can read the entire article for free by clicking here with my friend’s link
Introduction
DeepSeek recently introduced its models, including DeepSeek V3 and DeepSeek R1. These models have gained significant popularity in the AI community and on social media due to their impressive performance compared to models like OpenAI’s o1. Unlike OpenAI’s models, DeepSeek’s models are fully open-source and free to use.
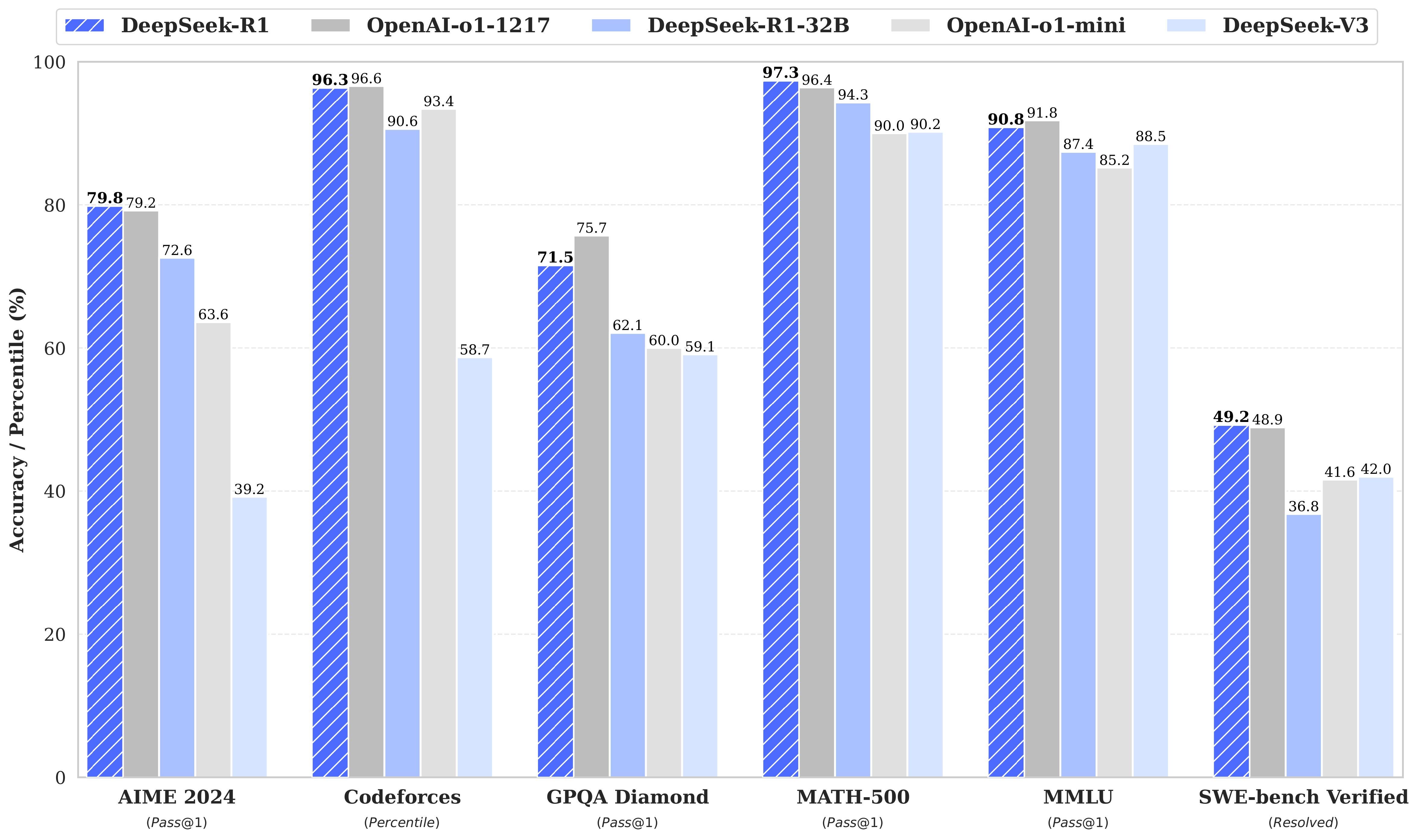
Since DeepSeek models are open-source and licensed under MIT, they are free to use for both personal and commercial purposes, and you can even run them locally. However, unless you have an insanely powerful machine, you won’t be able to run DeepSeek R1 on your local setup.
That’s where the smaller distilled models come in. DeepSeek has not only released the R1:671B model but also several dense models that are widely used in the research community.

