Cleanlab: Correct your data labels automatically and quickly
Data-centric AI without manually relabeling your data
I used an open-sourced library, cleanlab, to remove low-quality labels on an image dataset. The model trained on the dataset without low-quality data gained 4 percentage points of accuracy compared to the baseline model (trained on all data).

Improving data quality sounds easy enough. It’s essentially identifying and rectifying wrong labels. But the workload of manually checking data quality can quickly become insurmountable as the dataset scales.
What if we can automate that process? I didn’t know that this was possible until I encountered Cleanlab. This was the library that identified labeling errors in large image datasets like ImageNet.

What is cleanlab?

cleanlab is an open-sourced library that finds and fixes errors in any ML dataset. This data-centric AI package facilitates machine learning with messy, real-world data by providing clean labels during training.
In this post, I will walk through an example of how I’ve used cleanlab to improve the performance of a model in data-centric AI competition held by Andrew Ng. I will go through the following:
- Downloading the dataset
- Baseline model training (pre-trained Resnet50)
- Installing cleanlab
- Identifying data quality issues with cleanlab
- Resolving data quality issues
- Fine-tuning the same pre-trained Resnet50 model with cleaned data
- Compare the performance of the baseline model and the new model trained on cleaned data
All the codes in this post are in this Notebook. Follow along!
(Note: I will only post code snippets that do not run on their own. Please use the notebook if you’d like to replicate the results.)
Let’s get started.
Downloading the dataset
The dataset of the data-centric AI competition comprises handwritten images of Roman numerals from “I” to “X”. It has 2880 images from 10 categories, which are split into train and validation datasets.
Here is a random subset of the images. Right off the bat, we can see that one label is incorrect. In particular, the image on the rightmost column in the second row has an incorrect label of IX when it is an IV.
Baseline model training (Resnet50)
With the original dataset, we will train a baseline Resnet50 model. In the spirit of a data-centric competition, all entries to the competition have the same model. Thus, we will use this model for the baseline training.
def get_net():
base_model = tf.keras.applications.ResNet50(
input_shape=(32, 32, 3),
include_top=False,
weights=None,
)
base_model = tf.keras.Model(
base_model.inputs, outputs=[base_model.get_layer("conv2_block3_out").output]
)
inputs = tf.keras.Input(shape=(32, 32, 3))
x = tf.keras.applications.resnet.preprocess_input(inputs)
x = base_model(x)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(inputs, x)
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.0001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)After training for 100 epochs, the accuracy of the training set skyrocketed to 100%, and the training loss dropped to close to 0. The validation loss has fluctuated wildly, though. This is a case of underfitting, as there is not enough data for the model to generalize to the validation set.
The model didn’t do too well on the test set either. Overall, it has an accuracy of 59%.
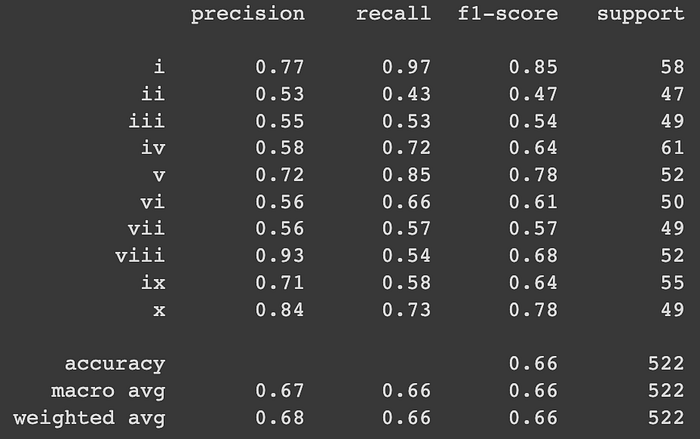
In particular, we see it is underperforming on the label “II”, often confusing it for “I” and “III”. We can say the same for “VIII”, which is often misclassified as “VII”.
Given its poor performance, what can we do about the model?
Typical suggestions would include “changing the architecture” or “hyperparameter tuning”. While valid, these suggestions ignore the fact that we have very little good data to work with. Any improvement to the model has little to no impact on the overall performance.
Instead of iterating on the model, let’s improve the dataset instead.
This is usually a long process. Practitioners need to explore the dataset and manually identify bad labels. This is not only slow but also an error-prone process.
Well, that’s if you don’t have Cleanlab. Cleanlab automatically finds and fixes label issues in your ML datasets.
Let’s try it out on this dataset and see how it improves our model.
Installing Cleanlab
pip install cleanlab scikerasPreparation
As cleanlab’s features require scikit-learn compatibility, we will need to adapt our Keras neural net accordingly. Fortunately, scikeras can handle that for us effortlessly.
from scikeras.wrappers import KerasClassifier
mdl = KerasClassifier(model=get_net, epochs=num_epochs, batch_size=8, verbose=0)Next, we use the cross_val_predict function to perform 5-fold cross-validation. This produces out-of-sample predicted probabilities for every data point in the dataset.
from sklearn.model_selection import cross_val_predict
num_crossval_folds = 5 # for efficiency; values like 5 or 10 will generally work better
pred_probs = cross_val_predict(
mdl,
images,
labels,
cv=num_crossval_folds,
method="predict_proba",
)Identifying data quality issues with cleanlab
Now comes the exciting part. We can identify poorly labeled samples with cleanlab.
from cleanlab.filter import find_label_issues
ranked_label_issues = find_label_issues(
labels=full_labels, pred_probs=pred_prob, return_indices_ranked_by="self_confidence"
)
print(f"Cleanlab found {len(ranked_label_issues)} label issues.")
>>>Cleanlab found 1282 label issues.Cleanlab identified over 1000 label issues in our (training and validation) dataset of fewer than 3,000 data points. That’s a significant number. Let’s see if Cleanlab is right.

We can already see some bad data here, especially those that I’ve highlighted above. These data points can pollute our dataset significantly.
Generate Overall Data Health Report
We can also get a health summary from Cleanlab.
from cleanlab.dataset import health_summary
health_summary(full_labels, pred_prob)Let’s see what the health report includes.
Overall Class Quality
This health report breaks down the label quality by class, giving practitioners an idea of what the weakest link in the dataset is.
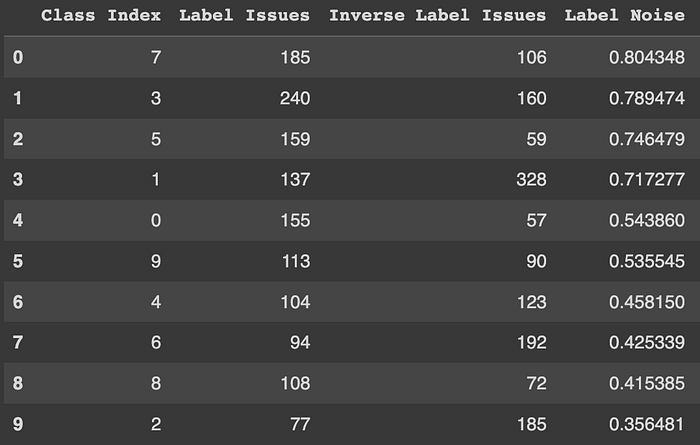
In our case, we see that the class with the highest label noise are classes 3, 7 and 5. These are “IV”, “VIII” and “VI” (Class 0 corresponds to “I”).
Recall that our model performed the worst in these classes. cleanlab’s finding provided an explanation — the model could not learn to effectively classify these classes because the data for these classes are noisy.
Class Overlap
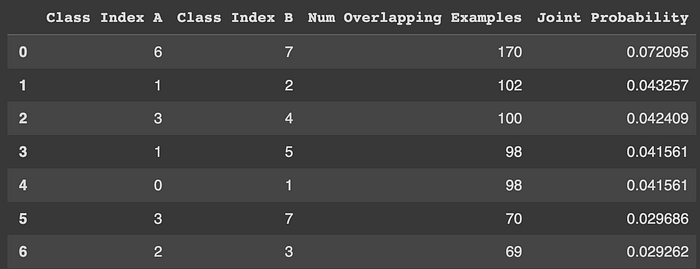
ceanlab also guesses if there are overlaps in our classes. Overlaps can occur when the definitions of the label are not mutually exclusive. It can also occur when two classes are mislabeled as one another.
In our case, we see that cleanlab is telling us that there are 125 overlapping examples in the class “VII” and “VIII” (from row 0). With this finding, we can explore the labels for classes “VII” and “VIII” and identify any mislabels.
Calculate Label Quality Score
We can also get the quality score of each label. A data point with a lower quality score has a higher chance of being incorrectly labeled. We can thus more confidently remove data points with low-quality scores from our dataset.
# Get quality scores
from cleanlab.rank import get_label_quality_scores
quality_scores = get_label_quality_scores(full_labels,pred_prob)Fixing problematic data
We now have a better idea of why our model is underperforming.
There are several ways that we can proceed from here:
- Remove all data that cleanlab deems problematic.
- Remove data with quality scores below a threshold. We define or remove a set number of data points.
- Manually mark the data for removal starting from the lowest quality score.
Approach 3 is the best. False positives are inevitable, so it’s best to keep the false positives (actually good data marked as low quality) in the training set.
Here, we use approach 2. In particular, we remove 10% of the data points that Cleanlab deems problematic from the training set. That turns out to be 142 samples.
Retraining model
Now, let’s retrain the model with the same model architecture, except with a different training and validation set. We will evaluate the model on the same unmodified test set.
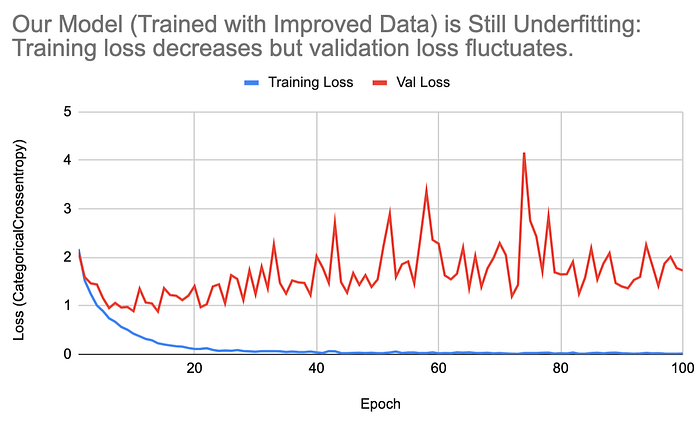
New model performance
When trained on the cleaned data, the model’s accuracy on the test set is 67%. This is a significant improvement from the previous 59% when the model is trained with dirty data and evaluated on the same test set.


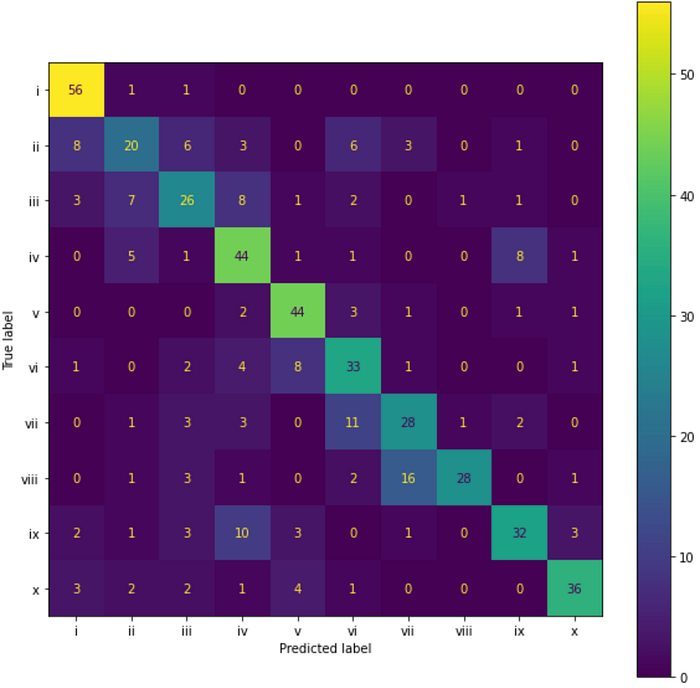
The removal of data points has helped the model become more accurate across all but two categories. We see a similar picture when comparing the confusion matrices.


Closing
“In many industries where giant data sets simply don’t exist, the focus has to shift from big data to good data.” — Andrew Ng
Recent years saw the data-centric AI movement garnering steam. A marked departure from a model-centric approach, data-centric AI seeks to improve data quality while keeping the model constant.
My experience as a data scientist corroborates his observation. Sure, the selection of an appropriate model or algorithm is critical at the beginning of the data science cycle. However, the marginal gains from optimizing the hyperparameters of a model dwindles quickly toward the end. That is when improving the quality of the datasets helps tremendously.
That’s why cleanlab is valuable. Trust me. I spent a painful week meticulously checking labels trying to stay awake. You do not want to do that.
Check out cleanlab’s documentation here.










