You're reading for free via Mukundan Sankar's Friend Link. Become a member to access the best of Medium.
10 No-Nonsense Machine Learning Tips for Beginners (Using Real-World Datasets)
Stop Overthinking and Start Building Models with Real-World Datasets
Do you want to get into machine learning? Good. You’re in for a ride. I have been in the Data field for over 8 years, and Machine Learning is what got me interested then, so I am writing about this! More about me here.
But here’s the truth: Most beginners get lost in the noise. They chase the hype — Neural Networks, Transformers, Deep Learning, and, who can forget — AI — and fall flat. The secret? Start simple, experiment, and get your hands dirty. You’ll learn faster than any tutorial can teach you.
These 10 tips cut the fluff. They focus on doing, not just theorizing. And to make it practical, I’ll show you how to use real-world datasets from the UCI Machine Learning Repository to build and train your first models.
Let’s get started.
1. Start Simple: Build Small Models First
Forget deep learning for now. It’s crucial to start with small, simple models. You're not ready for neural networks if you can’t explain Linear Regression or Decision Trees. These simple models work wonders for small datasets and lay a solid foundation for understanding the basics.
Example: Predict Housing Prices with Linear Regression
We’re using the Boston Housing Dataset. The goal? Predict house prices based on features like crime rate, number of rooms, and tax rate.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Load dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
columns = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT", "MEDV"]
data = pd.read_csv(url, sep='\s+', names=columns)
# Split data
X = data.drop(columns=["MEDV"])
y = data["MEDV"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train Linear Regression
model = LinearRegression()
model.fit(X_train, y_train)
# Evaluate
y_pred = model.predict(X_test)
print(f"Mean Squared Error: {mean_squared_error(y_test, y_pred):.2f}")
What’s Happening Here?
- We load the housing dataset (no fluff).
- Split it into training and testing datasets (80/20).
- Train a Linear Regression model to predict prices.
- Evaluate using Mean Squared Error (MSE).
The result? A basic model you can explain in 5 minutes.
2. Understand Your Data Before Training a Model
Raw data is full of stories. Don’t skip the step of exploring your dataset, visualizing relationships, and identifying weird outliers that could potentially screw up your model’s performance.
Example: Explore Relationships in the Wine Dataset
We’re using the Wine Dataset. This dataset classifies wine into three types based on 13 features.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the Wine Dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data"
columns = ["Class"] + [f"Feature_{i}" for i in range(1, 14)]
data = pd.read_csv(url, header=None, names=columns)
# Visualize relationships
sns.pairplot(data, hue="Class", diag_kind="kde")
plt.show()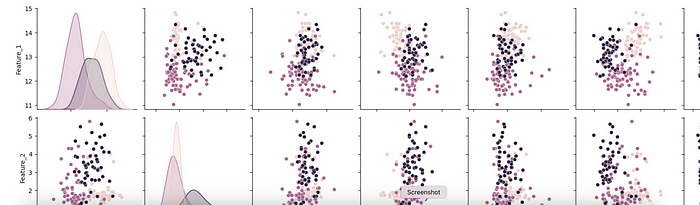
What’s Happening Here?
- The dataset has 3 wine Classes and 13 numerical features.
- A pairplot visualizes relationships between features.
- You’ll quickly see which features separate wine classes (some patterns will jump out).
Key Insight: Machine learning is about understanding the data first, not the model.
3. Clean and Preprocess Your Data
Remember, dirty data equals bad models. Your algorithm is not a mind reader. Missing values, non-numeric data, and inconsistent scales will negatively impact your results. So, clean and preprocess your data before training your model.
Example: Clean the Breast Cancer Dataset
The Breast Cancer Dataset contains some invalid entries represented by ?.
import numpy as np
# Load the dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
data = pd.read_csv(url, header=None)
# Replace '?' with NaN
data.replace("?", np.nan, inplace=True)
# Drop rows with missing values
data = data.dropna()
print(data.head())
What’s Happening Here?
- Replace invalid entries (?) with NaN.
- Drop rows with missing values.
- The cleaned data is ready for model training.
Lesson: Garbage in, garbage out. Clean your data.
4. Split Your Data Before You Do Anything Else
You’re fooling yourself if you evaluate your model on the same data you trained it on! Split your data into train and test data sets.
Example: Train-Test Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"Train size: {X_train.shape}, Test size: {X_test.shape}")
Why It Matters: Testing your model on unseen data simulates real-world performance.
5. Scale Your Data Before Training
Machine learning models don’t know that “age” and “income” are measured differently. Scale the features so all values have equal importance.
Example: Standardize Features
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)6. Cross-Validation: Test Your Model the Right Way
A single train-test split isn’t enough. Use cross-validation to test your model on multiple folds of data. We will use a different dataset here. This is the Banknotes Authentication dataset from UCI ML. You will notice how the Cross validation accuracy is different from the accuracy. Lower! Use the lower one. If your accuracy is giving you a higher percentage, and if you use that, you are wrong!
Example: Cross-Validation with Random Forest
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
model = RandomForestClassifier()
scores = cross_val_score(model, X, y, cv=5)
print(f"Cross-Validation Accuracy: {scores.mean():.2f}")
7. Choose the Right Features
Not all features matter. Use feature selection techniques to pick the most important ones.
from sklearn.feature_selection import SelectKBest, f_classif
X_new = SelectKBest(f_classif, k=3).fit_transform(X, y)
print(f"Selected Features Shape: {X_new.shape}")
8. Regularize to Avoid Overfitting
Overfitting happens when your model performs well on training data but fails on unseen data. Regularization helps fix it.
Example: Ridge Regression
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0)
ridge.fit(X_train_scaled, y_train)
print(f"Model Coefficients: {ridge.coef_}")
9. Tune Your Hyperparameters
Models have settings (hyperparameters) that need tweaking for better results. Use Grid Search to find the best ones.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
params = {'kernel': ['linear', 'rbf'], 'C': [0.1, 1, 10]}
grid = GridSearchCV(SVC(), params, cv=5)
grid.fit(X_train_scaled, y_train)
print(f"Best Parameters: {grid.best_params_}")
10. Evaluate Your Model with the Right Metrics
Accuracy isn’t enough. Look at metrics like precision, recall, and F1-score to measure your model’s performance.
from sklearn.metrics import classification_report
y_pred = model.predict(X_test_scaled)
print("Classification Report:")
print(classification_report(y_test, y_pred))
Final Words
You don’t need a PhD to learn machine learning. Start small. Build models. Break things. Learn from mistakes.
Use these tips, grab datasets from the UCI Repository, and start coding. You’ll get better one step at a time.
The best machine learning engineers aren’t the smartest — they’re the ones who just start. 🚀

